时间片管理
CFQ的时间片管理
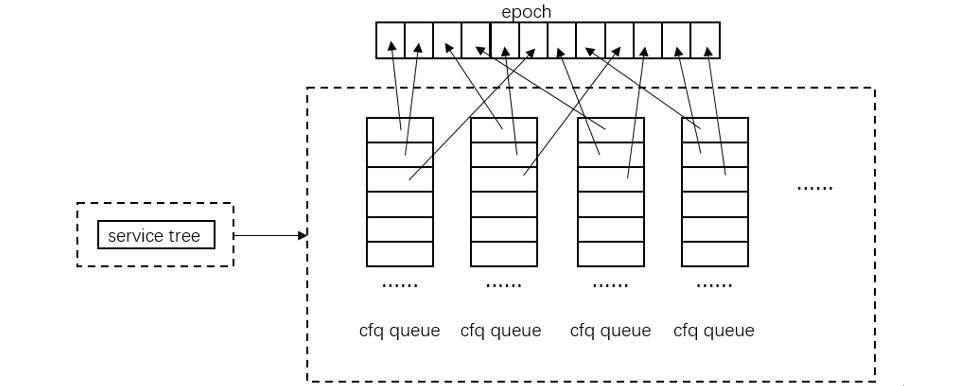
CFQ 的时间片管理如下图。每个请求队列 cfq queue 的时间片用完后,都要通过【选择 cfq group -> 选择 service tree -> 选择 cfq queue】的流程,从其自身维护的数据结构中找出下一个要被调度的请求队列,整个选择相当于根据一个优先级顺序不断地遍历这个数据结构。当一个 cfq queue 的时间片用尽,就要等到下一轮遍历回来才能被调度。
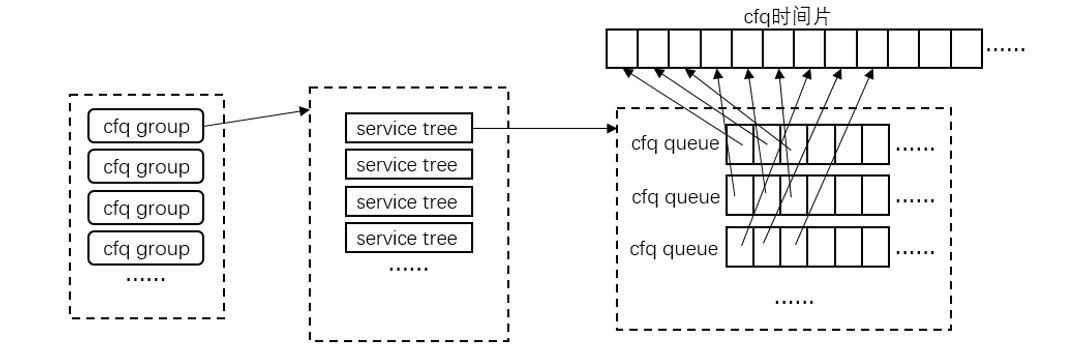
针对 cfq group、service tree、cfq queue 以及 cfq queue 中的 request,调度都不是顺序执行的,优先级高的将被优先执行。由于存在优先级,必须要考虑进程和请求饥饿的情况,因此 cfq 中引入一个 fifo 的数据结构来组织请求,并给每个请求一个等时间长度的 expire time,这样 fifo 中位于头部的请求的 expire time 就最小,只有在当前时间超过 expire time 的情况下,调度将绕过优先级,直接从 fifo 中取请求进行调度。
FIOS的时间片管理

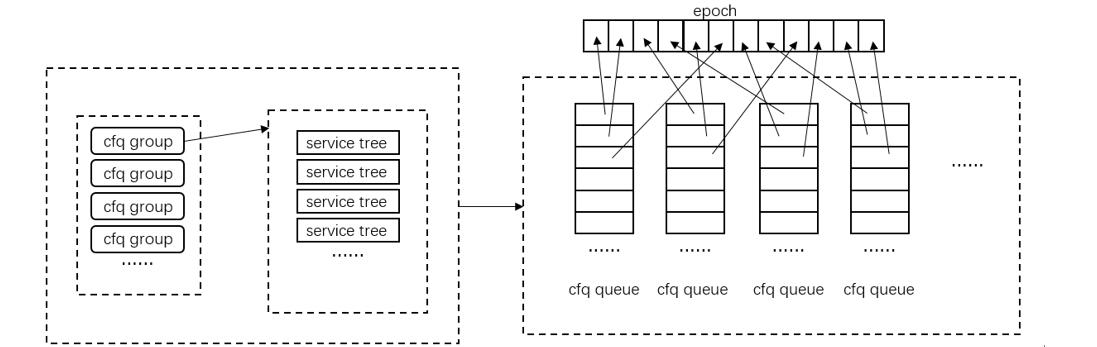
FIOS 论文中未提及该调度器是如何编码实现的,只说了他们设计了一个新的调度器。根据文章中提到的时间片管理方法,将其绘制成上面的图所示。一个 epoch 就是一组时间片的集合,相当于将 cfq 中的每个任务一组时间片,任务与任务之间顺序执行的方式进行打散,每轮整体循环中,某个任务的数个时间片可以在这轮循环中的任意时间点执行。而一旦某个任务的时间片都消耗完了,新的请求就只能等待到下一轮循环才能继续执行。文章中未提及到不同任务的请求队列之间是如何进行组织的,因此就默认采用链表的结构进行组织。
在 CFQ 上实现 FIOS
第一个版本(下面简称 fios1)的实现思路是:在原有的 cfq 的基础上,将每个请求队列连续的时间片打散。cfq 有一套复杂的请求队列选择方法,并且请求队列的选择是基于优先级进行的,也即在一定时间内,优先级高的队列比优先级低的队列被执行的次数更多。
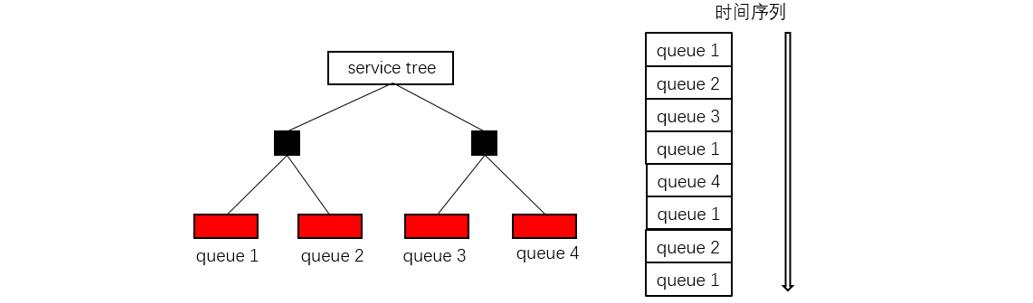
fios1 没有考虑请求队列的选取方式,而是将请求队列的选择视为一个黑盒。考虑在时间序列上,存在一个请求队列的顺序序列,例如下图所示,fios1 在时间序列上实现 epoch 的时间片管理,但是优先级高的请求队列会被更多的调度,由此导致不公平。
fios1 的第二个问题是遍历请求队列的过程存在问题。由于 group、service tree 以及请求队列存在优先级,将导致不公平的调度。由于 fios1 的时间片整体切换要满足以下条件: 1. 当前时间片序列中所有任务都没有可用的时间片,或 2. 当前有可用时间片的任务的队列中没有 IO 请求。
具体的实施方式是这样的: 1. 定义一个指针 P 指向当前的请求队列; 2. 从当前请求队列往后面遍历,判断请求队列是否有可用的时间片以及有可用时间片的请求队列中是否有 IO 请求; 3. 如果条件 2 满足,则对请求队列进行调度; 4. 如果条件 2 不满足,则一直取下一个请求队列,直到取出的请求队列与指针 P 指向的地址相同,即发生了一轮循环,表示没有可调度的请求队列,此时进行时间片的整体刷新。
上面的时间片刷新方法存在一个问题,如下图所示,如果请求队列按照循环队列的方式进行组织,则可以保证循环一轮后,每一个队列都有且只有被访问一次;而徜若请求队列的组织形式不是线性的,则会存在有些请求队列被访问多次,而有些队列完全没被访问到,例如图中的 queue 4 未被访问就可能判定需要刷新所有任务的时间片了。
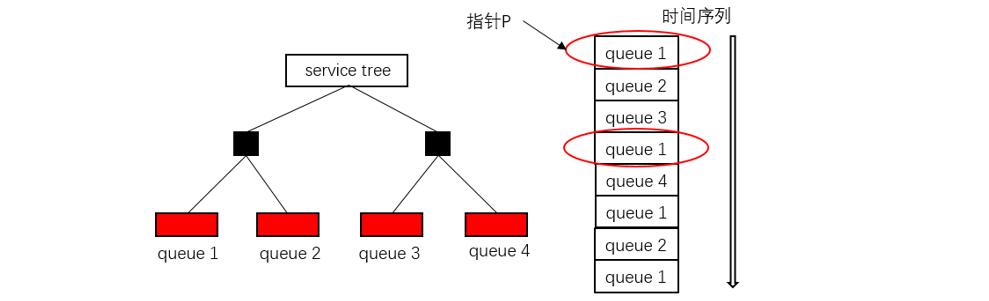
同样的由非线性组织的请求队列导致的第三个问题,即刷新所有任务的时间片时,有些请求队列没有被访问到,例如上图所示的 queue 4 就未被访问到。
FIOS2
在第二个实现的版本中,剔除了 group,并且只有一个 service tree 的结构,如下图所示。虽然避免了多个 service tree 的选择问题,但是 service tree 内部仍然是按照红黑树的方式进行组织的,所以仍然存在优先级影响请求队列访问的公平性。
读写干扰管理
FIOS 论文中的读写干扰管理
由于 flash 的读写性能差异,FIOS 采用读优先策略,保证当任务的请求队列中有读请求存在时,优先执行读请求,同时将阻塞写请求,直到完成完整的数据读取。只有在写入请求已经发出的情况下,后续到来的读请求才会被写请求阻塞。这种策略会导致额外的写请求排队时间,但是由于读请求更快,所以相对而言写请求的额外排队时间较小。读优先的策略仍然受制于基于 epoch 的时间片管理机制,所以能够防止其他任务的写请求陷入饥饿。但是无法保证某个任务自身的读请求不会阻塞自身的写请求。关于这点文章中未给出准确的处理方法。
关于在 CFQ 上实现读优先策略
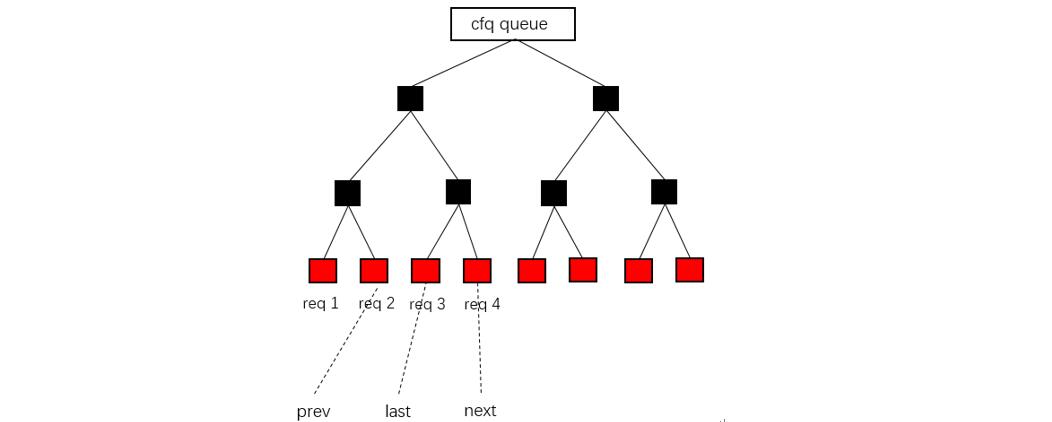
上图是 cfq 现有的取请求操作。对请求队列的每一次调度,都要进行如下的步骤: 1. last 表示该请求队列上一次调度的请求所在的红黑树位置 2. prev 表示位于 last 前一个的请求 3. next 表示位于 last 后一个的请求 4. 如果 prev 和 next 其中一个是同步请求,则调度同步请求; 5. 如果两个请求都是同步或者都是异步请求,则执行步骤 6; 6. 根据 last 请求对应的地址,计算 prev 和 next 到 last 之间的距离; 7. 判断 prev 和 next 是否 wrapped,从中取出一个请求进行调度。
在实现 FIOS 的读优先策略时,考虑到遍历的效率问题,所以没有通过整个红黑树的遍历来寻找读请求,而是修改了上面的取请求操作。对于 last 前后的两个请求 prev 和 next,进行了简单的读请求判断。这种处理存在问题,如果 prev 和 next 都不是读请求,而读请求位于该请求队列的其他位置,则这一轮调度就没有“读优先”了。
I/O 并行性
FIOS 文章中给了两种方法进行并行 IO 的开销计算。第一种方法是:首先校准不同数据大小的读/写请求的开销时间,并根据校准结果的类型(读/写)和大小,计算出 IO 请求的时间开销。文章中只校准了四种情况:4KB 读、128KB 读、4KB 写、128KB 写。这种方法必须基于一个大前提:假设 IO 请求的时间开销和数据大小之间是线性关系。
文中还给了第二个方法,用总的请求执行时间开销直接除以请求的数量。

在实现 IO 并行性时,设置一个变量指示请求下发的数量,在一个请求队列的时间片用完或者队列中没有新的 IO 请求时,计算平均每个请求的时间开销,然后用新的时间开销来重新计算请求队列的剩余时间片。
适当的 I/O Anticipation
FIOS 中设定的 Anticipation 时间长度的公式如下所示,其 α 为 0.5 作为默认值。
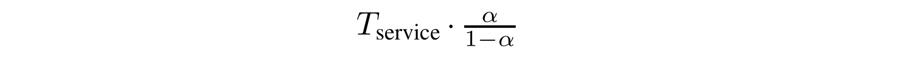
在实现的时候,设定 4 个变量,分别如下:
- cfq_alpha = 50,表示 α 的值,默认为 50,取值区间为 0-99;
- cfq_tservice = NSEC_PER_SEC / 125,表示初始的 Tservice 值,默认取 8ms;
- cfq_tsrv_nr = 1,表示在 IO anticipation 期间调度的请求数量;
- cfq_tsrv_sum = NSEC_PER_SEC / 125,表示在 Anticipation 期间调度的时间开销;
根据上面的 4 个值,每当在 Anticipation 期间执行了请求,就更新上面的四个变量。
(完)