block layer 的最核心功能可分为两部分——接受上层提交的请求;对请求进行调度。其中 block layer 的入口函数为:submit_bio。如下图所示:
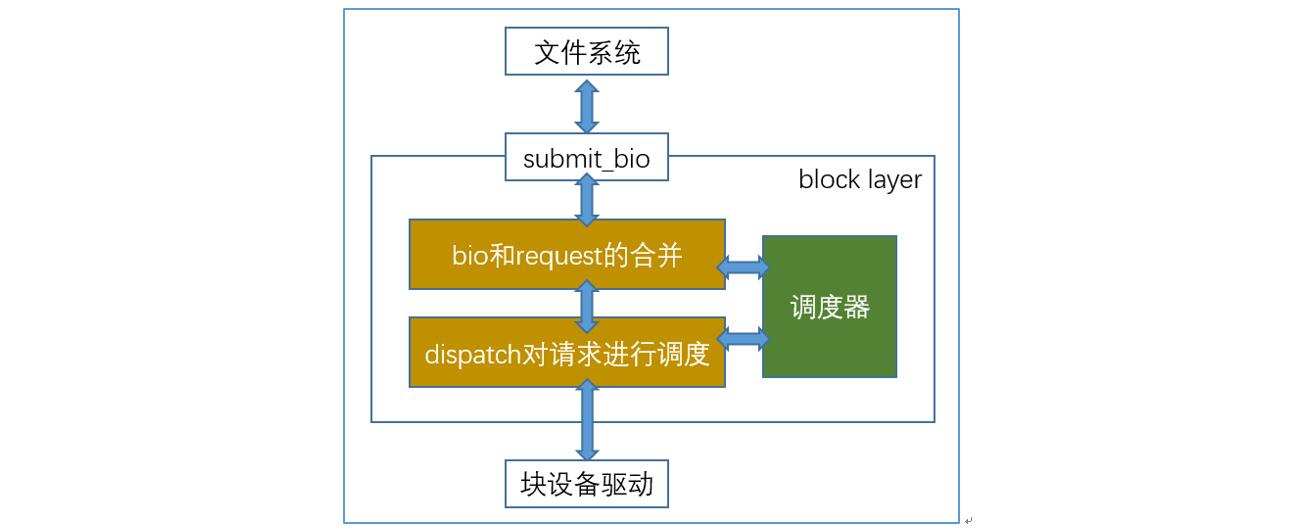
文件系统请求提交 - submit_bio
接口函数 submit_bio 被调用后,将对 bio 进行合并,然后尝试合并 request,期间会调用调度器中定义的方法,完成合并后,请求将等待被调度。调度阶段,将决定哪个请求被下发执行,这里也会涉及到调度器的决策。bio的结构主要如下图:
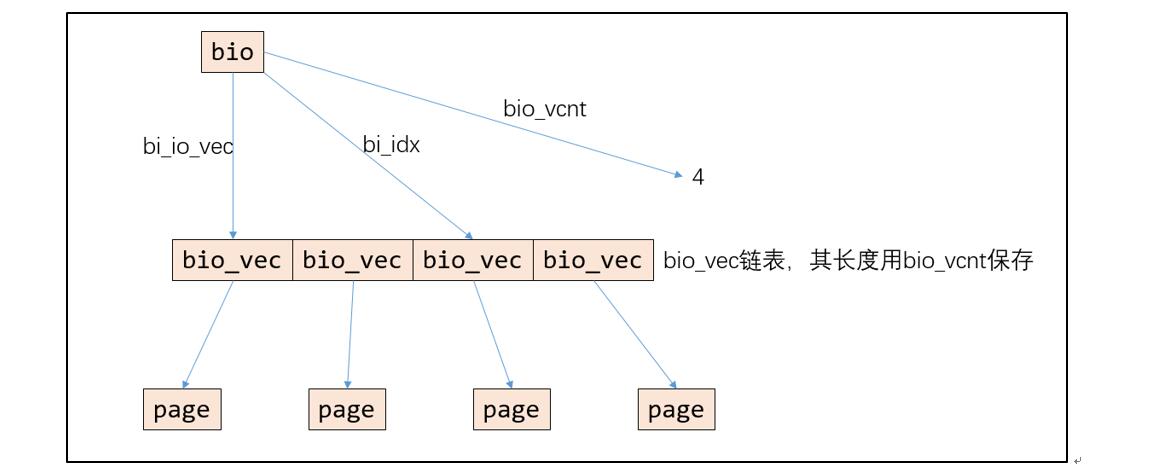
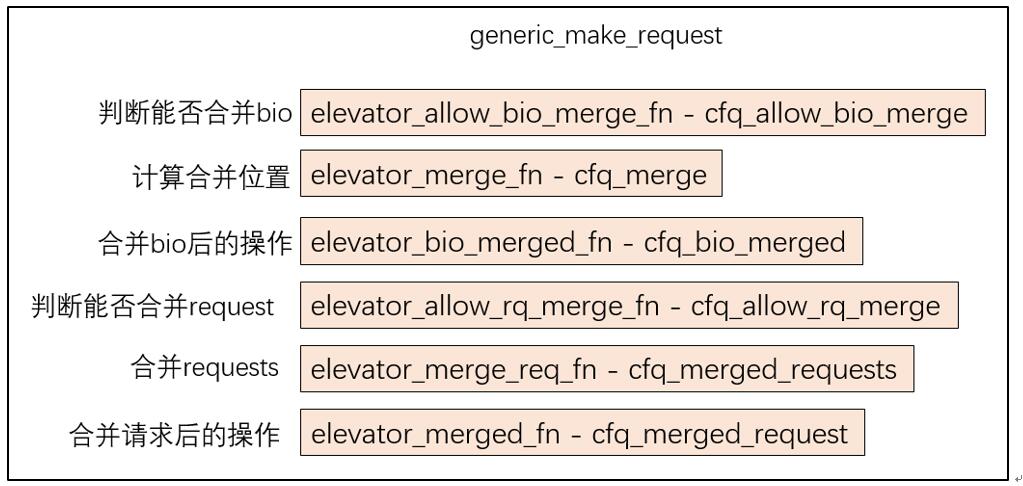
每个 bio 中包括一个 bio_io_vec 数组,其中保存的每个单元是 bio_vec 结构体数据,而每个 bio_vec 分别对应到一个 page 的数据区域。bio 用变量 bi_idx 来进行索引,用 bio_vcnt 计数 bio_vec 的数量。请求的合并执行过程中,主要进行下面的六个步骤,分别对应调度器的六个函数调用:
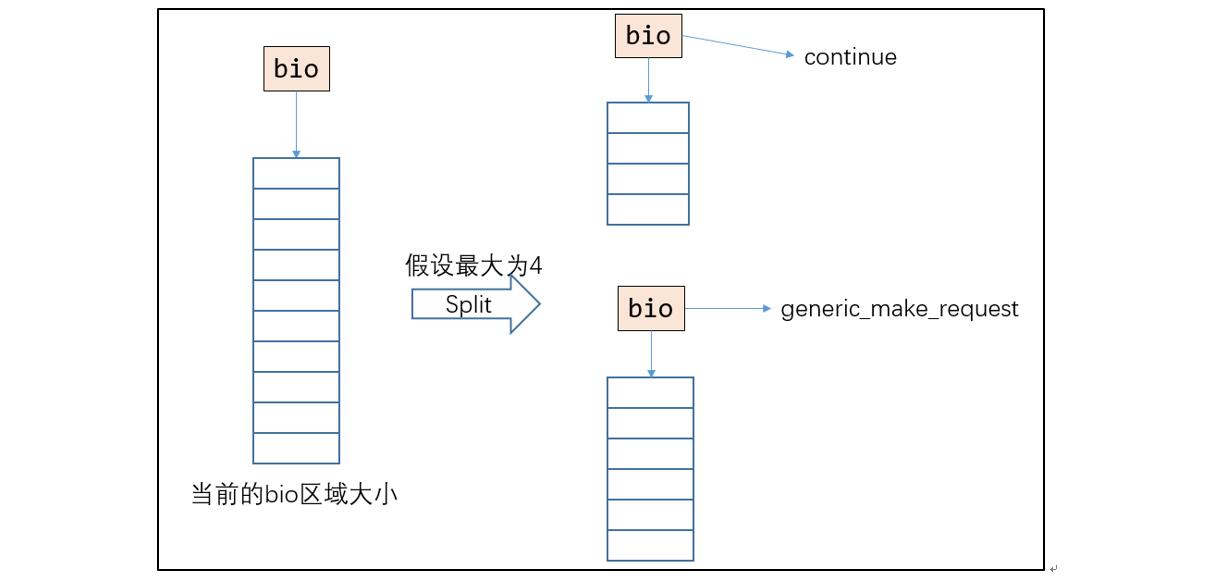
假设执行合并的操作都失败了,即:没有能够合并的 bio。那么这个下发下来的 bio 就必须要填入一个新创建的 request 中,因此就涉及到 request 的创建了。在这里要对过大的 bio 进行切分,切分的操作如下所示。如果当前的 bio 大于一个阈值,则从中间某个位置切开,变成两个 bio。第一个 bio 的大小是能够接受的最大值,后一个 bio 将被继续调用 make request 函数进行迭代式的生成请求。
当一个 request 创建初始化,就要将其插入到相应的队列中,cfq_insert_request() 函数完成这个功能,和 deadline 调度器相似,request 会被放入两个队列里,一个是按照起始扇区号排列的红黑树 (sort_list),一个是按响应期限排列的链表 (fifo)。
提交阶段的关键函数调用关系如下图所示:
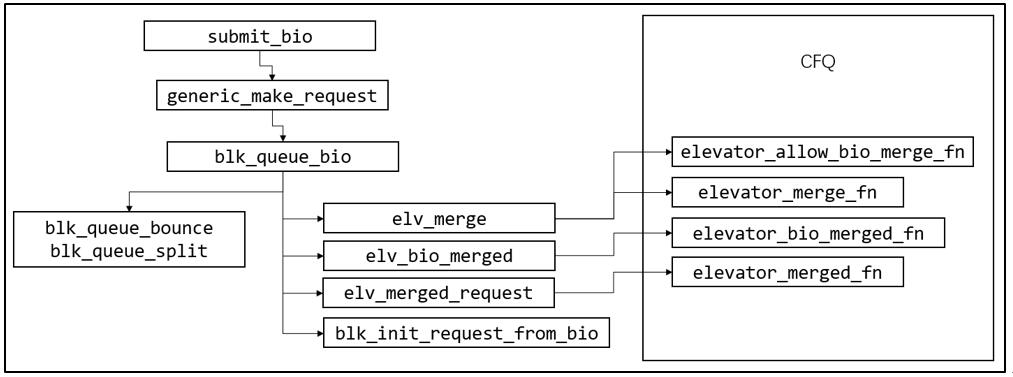
调度器请求派发 - dispatch
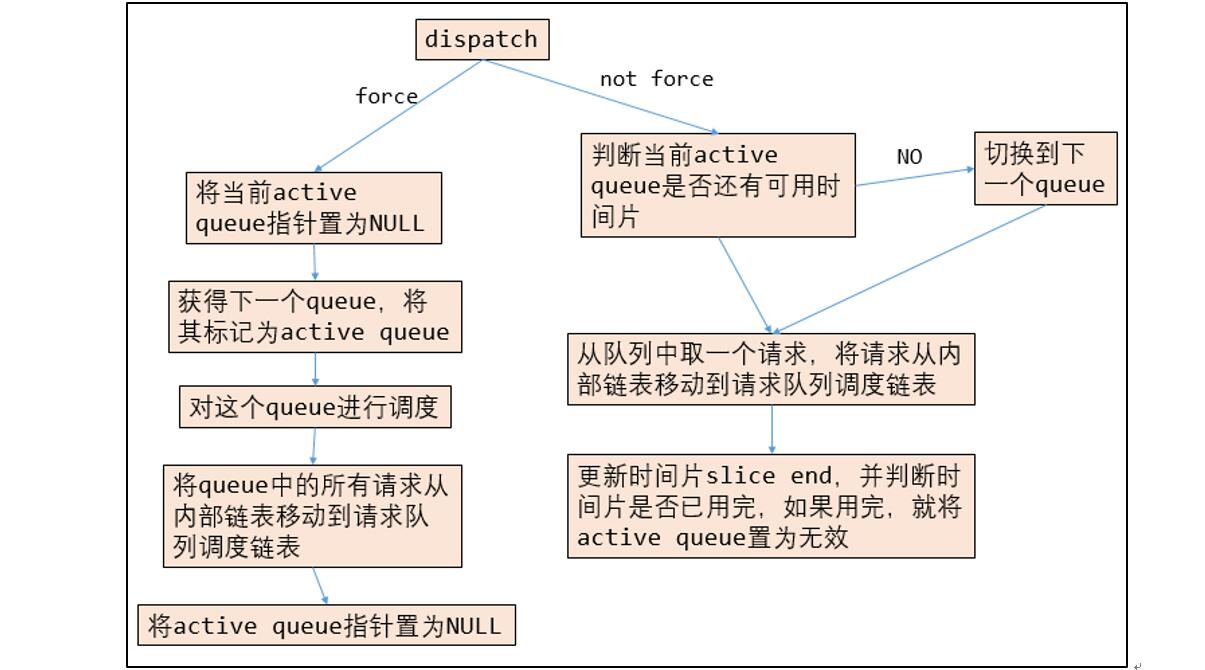
dispatch 部分主要是对请求进行调度,调度步骤如下图所示。调度分成两部分,强制调度和非强制调度。如果是强制调度,则将整个 queue 中的请求全部推到调度队列中;如果调度的方式是非强制的调度,则需要通过调度器进行操作,即选择要对哪一个队列中的哪一个请求进行调度。
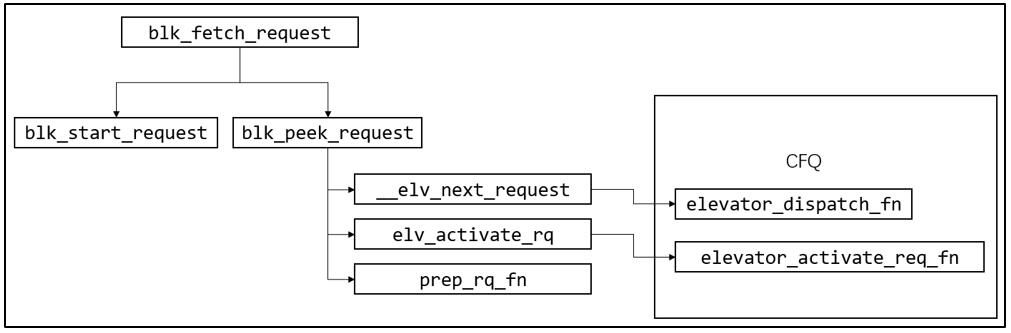
派发阶段的关键函数调用关系如下图所示:
一图流解释 CFQ 源码结构
如下图所示。点这里下载原图 CFQ.bmp.zip。
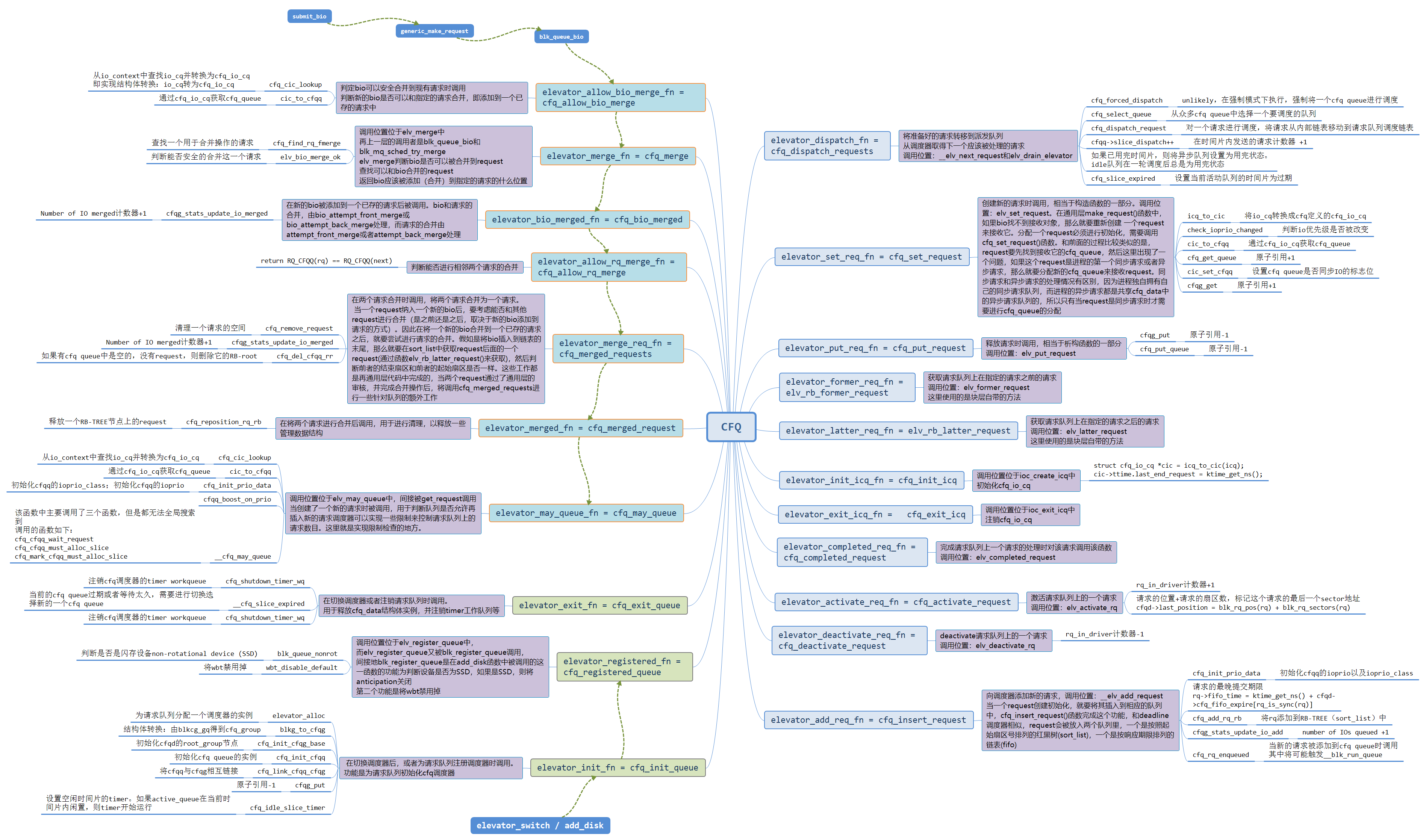
大致上可以将 CFQ 分为两个部分——请求的【入】与【出】。除了上图左下角绿色部分的注册注销相关的入口函数,左半边是 IO 请求从 submit_bio 下来之后的调用路径;右边部分是在派发阶段,IO 调度器选择派发哪一个请求的接口。制图不容易,可能存在纰漏,不过导师和师兄也检查过了,应该没有遗漏的。
(完)