本文是一篇类似于文献综述的东西,做点前期调研。
随着区块链项目的火热,很多传统技术结合区块链技术都取得了一定程度上的成功。2014 年 Juan Benet 成立了 Protocol Labs 并在开源社区的帮助下发展出了 IPFS[1]:一个去中心化的分布式文件系统。IPFS 的下层构建于对等网络交换协议,其核心是用于索引数据的分布式哈希表(DHT)。
分布式哈希表的研究伊始就是为了开发点对点网络系统,以便将分散在网络中各处的存储资源利用起来。但是在上个世纪末,局限于当时的技术条件,所设计出的半分布式系统没能够很好的达到要求,中央索引服务器容易受到攻击,其次每次搜索都会将查询消息广播给网络中的每个节点,效率非常低;之后诞生的第一个完全分布式系统,设计了一套基于关键值的转送方法,在这个方法中,每个文件与一个关键值相结合,而拥有相似关键值的文件会被相似的节点构成的集合所保管。于是查询消息就可以根据它所提供的关键值被转送到该集合,而不需要经过所有的节点。虽然解决了效率低下的问题,却不能够保证数据在网络中一定被找到。
直到 21 世纪初,最初的四项分布式哈希表技术同时于 2001 年被发表。
目录
- 相关研究
- Kademlia DHT:基于异或度量的分布式哈希表
- 异或度量的距离
- kad 节点维护
- Kad 协议
- 键值对的存储:STORE
- 节点查找:FIND_NODE
- 查找值:FIND_VALUE
- 新节点加入 kad 网络
- S/Kademlia:基于密钥的安全路由方法
- 针对 Kademlia 的攻击
- 安全的节点 ID 分配
- 通过不相交的路径进行查找
- 参考文献
相关研究
CAN DHT:Sylvia Paul Ratnasamy 等学者提出了内容可寻址网络(CAN DHT)[2]。CAN 被设计为可扩展、可容错、自组织的分布式哈希表,在设计上类似于一个多维度的笛卡尔坐标空间,网络中的每个节点都可以在空间中被标识出来。CAN 的每个节点维护一个路由表,保存每个邻居的IP地址和虚拟空间中的坐标区域,节点可以将消息路由到坐标空间中的目标区域,通过这种方式将整个网络组织起来。
Chord DHT:Ion Stoica 等学者提出了 Chord DHT[3]。Chord 方法通过将节点的 ID 从小到大串成一个圆环,从而覆盖整个网络,每个数据被保存在距离数据键值最近的后向节点处。Chord 采用非线性查找算法,即相似二分法的查找方法,收敛速度可以非常快,路由复杂度可以降低到节点数目的对数。
Pastry DHT:Antony Rowstron 和 Peter Drusche 提出了 Pastry DHT[4]。与 Chord 类似,Pastry 也采用环形网络拓扑,将每个节点的哈希标识符串联成一个环,与 Chord 的不同之处在于,Pastry 方法引入分级的思想,其不直接用节点哈希值构建环,而是只取节点哈希值的前 a 位,后面的 b 位则作为环上某个节点的叶子节点。这样的好处是极大的减少了环的空间大小,可以减少路由的时间;另一个不同点在于,Pastry 方法的数据是保存在距离数据键值最接近的节点上,而不仅仅是后向节点中。
Tapestry DHT:Ben Y. Zhao 等学者提出了 Tapestry DHT。在 Tapestry[5] 网络中,每个节点都会为自己分配一个全局唯一的节点 ID,同时在整个网络中有一个全网唯一的根节点 ID,所有节点在网络中构成一个树形拓扑,数据保存在与数据的键值最相近的节点上。
Kademlia DHT:2002 年美国纽约大学的 Petar P. Maymounkov 和 David Mazieres 创新性地提出了 Kademlia DHT[6],该方法通过对任意两个节点 ID 做异或运算,得到的值作为这两个节点的距离度量。通过这种距离的度量建立起了全新的二叉树形网络拓扑结构,与前面的四种方法相比,极大的提高了路由查询速度。在 Kademlia 网络中,某个节点到其他任意节点之间的距离全网唯一,同时在保存数据时,目标数据将被保存在距离数据键值最近的N个节点中,即当有 N-1 个保存了某个数据的节点离线,仍然能保证 Kademlia 网络正常提供目标数据。
S/Kademlia DHT:2007 年 Ingmar Baumgart 和 Sebastian Mies 从安全性和抗干扰的角度,提出了基于 Kademlia DHT 的一个改进方法:S/Kademlia DHT[7]。S/Kademlia 能够抵抗日蚀攻击、女巫攻击、客户流失攻击、敌对路由攻击、拒绝服务攻击,另外在节点查找方面,S/Kademlia 提出了通过不相交的路径进行查找的方法,进一步缩减了查找的时间复杂度。
在应用方面,许多著名的大学和科研机构都参与了各种对等网络的建设: - Sun Microsystems 在 2001 年开发了 JXTA(Juxtapose),一种开源对等协议; - 普林斯顿大学于 2003 年创建了 CoDeeN,一个应用了对等网络思想的 Web 缓存系统; - Neoteric 于 2004 年发布 Warez P2P,这是一个使用 Ares 网络的专有点对点文件共享服务; - I2P Team 维护的隐形网计划匿名网络项目; - eMule Team 维护的基于 eDonkey 网络的开源 P2P 文件共享软件; - 基于 Kademlia DHT 的分布式 P2P 文件分享网络被广泛用于风暴僵尸网络节点之间通信; - BitTorrent[8] 协议,基于 Kademlia DHT 的用于对等网络中进行文件分享的网络协议;
最后是近几年大火的区块链项目明星 IPFS,以及运行在其上的激励层 FileCoin。IPFS 中的 DHT 设计主要基于 S/Kademlia 算法,同时又结合了 Chord 的优点,与 BitTorrent 相比较,IPFS 具有更加安全可靠的设计,并且由于 IPFS 的最小单位是块存储,并且增加了快数据的去重,因此 IPFS 具有更少的冗余数据,能够更加充分的使用存储空间。此外 IPFS 还引入了激励层,鼓励用户将存储设备共享出来,并倡导互惠互利。以上种种优点使得 IPFS 被寄予很大的期望。
Kademlia DHT:基于异或度量的分布式哈希表
A Peer-to-Peer Information System Based on the XOR Metric.
Kademlia DHT,以下简称 kad,采用了 160 位(SHA-1)长度的 key,网络中的每个节点都有唯一的 key,称为节点 ID,这里可以简单的随机生成长度与 SHA-1 哈希值等长的 160 位作为节点的 ID。每个数据块都有对应的 key(计算 SHA-1),以 <key, value> 的形式存储在距离该数据 key 最近的节点上,这里涉及到两个哈希值距离的概念。
异或度量的距离
kad 通过直接计算两个哈希值的异或,得到的结果称为异或距离,例如:
异或运算有如下的规律:
根据异或的运算规律,对于任意一个 x,给定一个距离
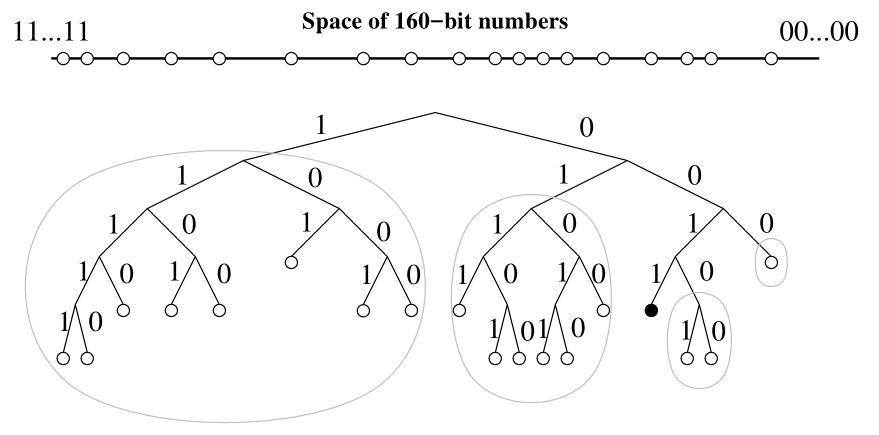
kad 通过将 160bit 的 key 用二叉树存储,例如图中黑色的点对应 0011,表示该节点距离当前节点的异或距离为 0011,假设当前节点的 key 是 1010,则可以计算出黑色节点对应的 key 为
kad 节点维护
每个 kad 节点都要保存一部分路由信息,节点查询时通过节点中继的方式将 kad 联成一张网络。前面提到对于 160bit 长的 key,将位的值映射到二叉树的左右节点上,从而加快查询速度。每个节点在维护路由表时,也是通过类似的方式实现的。每个节点有 160 个桶,称为
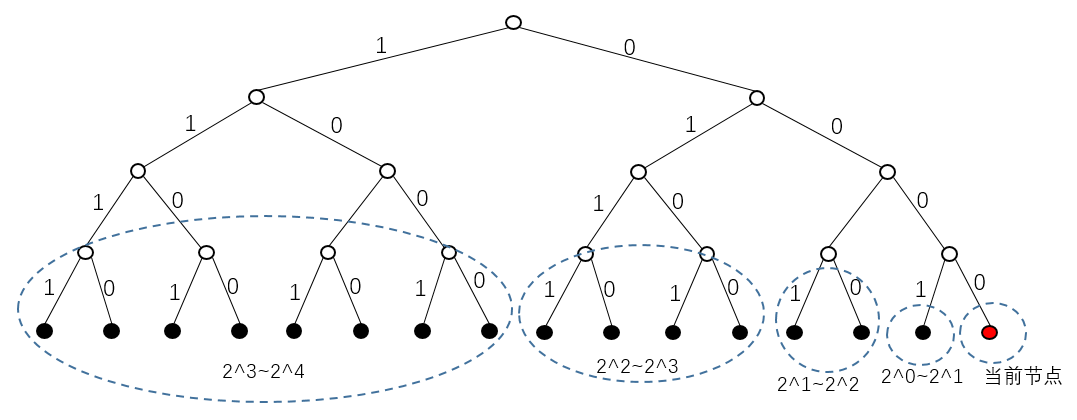
最右边的节点 0000 表示距离自己为 0000 的节点,即保存节点自身信息,向左的每个桶保存距自己 <IP addr, UDP port, Node ID> 的格式保存。
k-buckets 有大小限制,每个 bucket 中存储的节点数不能超过 k(文章中设定
kad 的更新规则基于这样的前提:在线时间更长的节点,之后一小时在线的概率也越高。下图取自论文,横坐标表示在线的时间,单位为分钟,纵坐标表示已在线
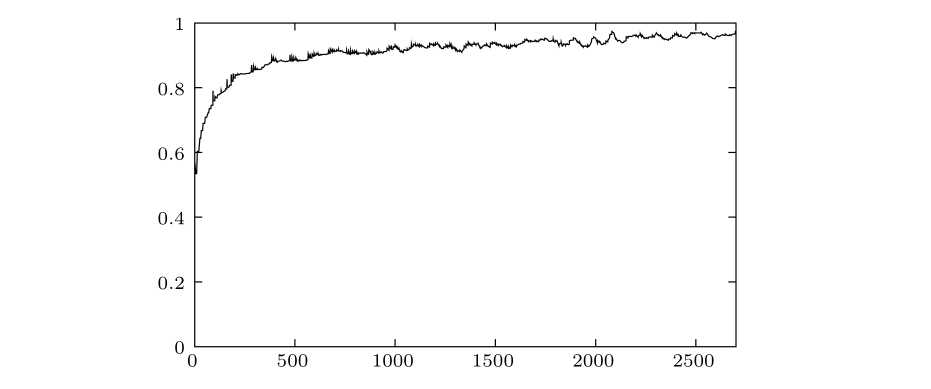
当节点与任意其他节点建立连接(不论是主动请求或被动响应),该节点都将使用上面的方法更新自己的 k-buckets。为了减少无效节点对查询过程的延迟影响,kad 要求定期对未更新过的节点进行存活检测,例如每隔一小时,就将桶中上一小时内未更新过的节点取出,发起 PING 请求,若节点不存在,则将节点信息从桶中删除。
Kad 协议
Kad 协议包含四个 RPCs,分别为: - PING:检测一个节点是否在线 - STORE:请求一个节点保存 <key, value> 数据 - FIND_NODE:从一个节点请求距离目标 key 最接近的 k 个节点数据,返回的节点数据为 <IP addr, UDP port, Node ID> 的三元组 - FIND_VALUE:与 FIND_NODE 的操作类似,如果被请求的节点无 <key, value> 数据,则返回 k 个 <IP addr, UDP port, Node ID> 的三元组;如果被请求的节点保存有对应 key 的 <key, value>,则返回对应的 value
键值对的存储:STORE
当需要存储一个键值对时,首先通过节点查找算法找到距离数据 key 最接近的
为了避免过度缓存,键值对有一个有效时间,文章中举例的是 24 小时,即键值对在存储到一个节点后,过 24 小时后就会将该键值对删除。数据提交者需要定期向存储有这些数据的节点发起“续存”的请求,即更新该键值对的有效时间,以保证该数据不会被到期删除。另外 kad 还建议对距离 key 越近的节点,该节点保存的对应数据有效时间越长。采用这种定期更新的方式还有另一个好处,kad 网络中随着时间的推移,会有新的节点加入,同时会有节点离开,因此定期更新可以保证数据尽可能在距离 key 最接近的节点集合上。
节点查找:FIND_NODE
对于已知的 key,从当前的 kad 网络中找到距离该 key 最接近的 <IP addr, UDP port, Node ID>)的过程称为 kad 节点查找。kad 采用递归的方式进行节点查找,过程如下: 1. 查找发起者从自己的桶中筛选出距离目标 key 最近的
查找值:FIND_VALUE
查找值时,通过 FIND_VALUE 不断逼近距离目标 key 最接近的节点,一旦查询过程中有任意一个节点返回了所查找的 value,FIND_VALUE 的查询过程就结束。考虑到加快查找的效率,查找结束后,发起者可以将 <key, value> 缓存到距离 key 最接近的但是没有存储该键值对的数个节点上。
新节点加入 kad 网络
- 通过任意途径,获得一个已经在 kad 网络中的节点信息,将该节点加入桶中
- 向该节点发起 FIND_NODE 的请求,查找距离当前节点自身 ID 最近的
个节点 - 递归过程中不断刷新自己的 k-buckets
Kademlia 原文中还讨论了实现上的一些细节,例如通过一些方式减少查询所需时间,以加快查找速度等,这里不深入讨论。
S/Kademlia:基于密钥的安全路由方法
Kademlia 方法很容易被攻击,Ingmar Baumgart 和 Sebastian Mies 在 Kademlia 的基础上,构建了一套基于密钥的安全路由协议,即 S/Kademlia,以下简称 S/kad,它通过在多个不相交的路径上使用并行查找来抵御常见的攻击,通过一系列约定限制自由生成节点 ID 并引入可靠的对等体广播,来达到安全路由的目的。
针对 Kademlia 的攻击
- 攻击底层网络:攻击者可能能够侦听或修改任意数据包,对底层的攻击可能导致拒绝服务攻击
- 攻击覆盖路由
- 日蚀攻击:攻击者在网络中部署数个对抗节点,使得部分消息在至少一个对抗节点上路由,从而使攻击者能够控制覆盖网络的一部分
- 女巫攻击:攻击者在网络中部署大量节点,直到能够完全控制整个 kad 网络的一部分
- 流失攻击:攻击者通过在网络中所控制的某些节点,引发高流失,直到网络稳定性失效
- 对抗路由攻击:被攻击者控制的节点在响应查询请求时,返回对抗路由的信息(生成最接近查询 key 的节点 ID),使得请求发起者无法正确找到目标
- 其他攻击
- 拒绝服务攻击:攻击者消耗节点的资源,使其无法向 kad 网络提供服务
- 对数据存储的攻击
安全的节点 ID 分配
由于 kad 随机任意生成 Node ID 的方式可以引发多种攻击,S/kad 使用散列公钥的方式生成 Node ID,并使用公钥对节点交换的消息进行签名。 - 弱签名:弱签名不会签署整个消息,它仅限于 IP 地址、端口和时间戳 - 强签名:签署消息的全部内容,确保消息的完整性
密钥对(节点 ID)的生成: - 监督签名:签名的公钥由可信赖的证书颁发机构签名 - 加密拼图签名:在没有值得信赖的证书颁发机构的情况下,需要通过加密拼图来阻止日蚀和女巫攻击
S/kad 的加密拼图方法分两个步骤,下图取自 S/kad 原文,左图是静态的加密拼图方法,右图是动态加密拼图方法,如果节点收到签名消息,它可以首先验证其签名,然后检查加密拼图是否已解决。
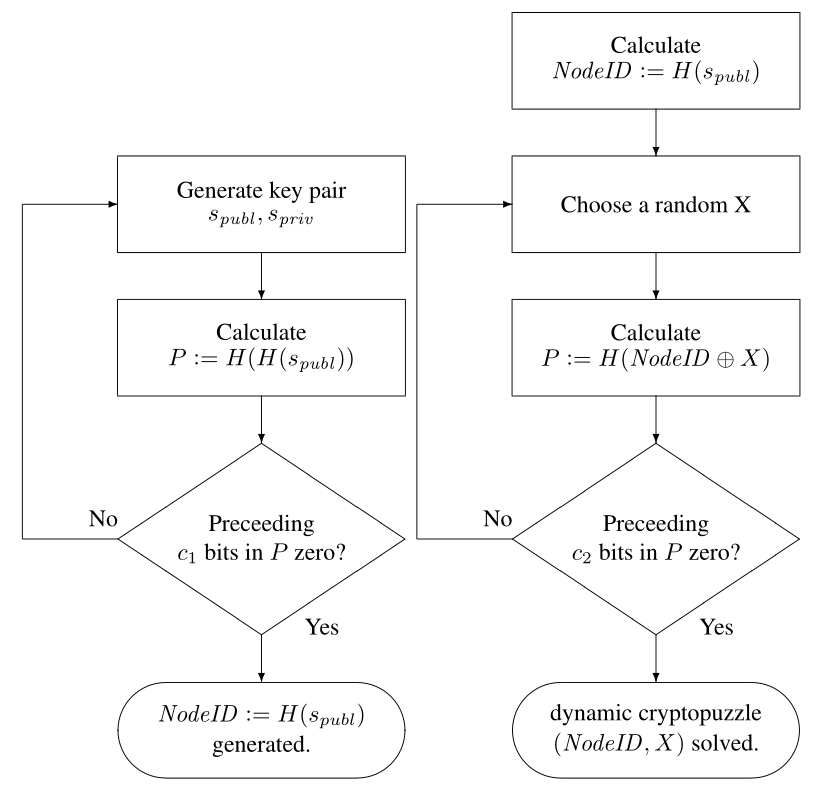
- 静态加密拼图
- 生成密钥对
- 计算
- 判断
的前 个 bit 是否都为 0 - 若步骤 3 满足条件,则
,否则转到步骤 1
- 生成密钥对
- 动态加密拼图
- 由静态加密拼图生成了
- 选择一个随机数
- 计算
- 判断
的前 个 bit 是否都为 0 - 若步骤 4 满足条件,则动态拼图(
)完成,否则转到步骤 2
- 由静态加密拼图生成了
通过不相交的路径进行查找
kad 直接通过迭代的方式查找距离目标最近的 k 个节点,S/kad 使用
参考文献
- [1] Benet J . IPFS - Content Addressed, Versioned, P2P File System (DRAFT 3)[J]. Eprint Arxiv, 2014.
- [2] Ratnasamy S P . A Scalable Content-Addressable Network[C]// Conference on Applications. ACM, 2001.
- [3] Stoica I, Morris R T, Karger D R, et al. Chord: A scalable peer-to-peer lookup service for internet applications[J]. acm special interest group on data communication, 2001, 31(4): 149-160.
- [4] Rowstron A I, Druschel P. Pastry : Scalable, decentralized object location, and routing for large-scale peer-to-peer systems[J]. Lecture Notes in Computer Science, 2001: 329-350.
- [5] Zhao B Y, Huang L, Stribling J, et al. Tapestry: a resilient global-scale overlay for service deployment[J]. IEEE Journal on Selected Areas in Communications, 2004, 22(1): 41-53.
- [6] Maymounkov P, Mazières D. Kademlia: A Peer-to-Peer Information System Based on the XOR Metric[C]// Revised Papers from the First International Workshop on Peer-to-peer Systems. 2002.
- [7] Baumgart I , Mies S . S/Kademlia: A practicable approach towards secure key-based routing[C]// Parallel and Distributed Systems, 2007 International Conference on. IEEE, 2008.
- [8] Pouwelse J, Epema D, Sips H. The bittorrent p2p file-sharing system: measurements and analysis[C]// International Conference on Peer-to-peer Systems. 2005.