C 标准库中对内存拷贝的操作位于头文件 <string.h>,其中涉及到内存拷贝的函数有:
- memcpy:内存拷贝,存在内存重叠的风险,源地址空间与目的地址空间的数据安全皆无法保障
- memmove:内存拷贝,可以保证目的地址空间数据的安全(不越界的情况下),但仍可能破坏源地址空间的数据
- mempcpy:内存拷贝,返回目的地址空间拷贝末尾后一个地址
- memccpy:内存拷贝,遇到指定字节时停止,返回该字节后一个地址;若未遇到指定字节,则全部拷贝并返回 NULL
- strcpy:字符串拷贝,返回目的地址空间的首地址,与 memcpy 一样存在内存重叠风险
- stpcpy:字符串拷贝,返回目的地址空间字符串末尾
'\0'后的一个地址 - strncpy:字符串拷贝,拷贝不超过 n 个字节的字符串,返回首地址
- stpncpy:字符串拷贝,拷贝不超过 n 个字节的字符串,返回目的地址空间字符串末尾
'\0'后的一个地址(或目的地址空间的尾地址)
1. memcpy
内存拷贝,从 srcpp 指向的地址开始,拷贝 len 长度的数据到 dstpp 起始的地址,源码如下。
1 | void *memcpy (void *dstpp, const void *srcpp, size_t len) |
其中有宏声明为: 1
2
3
4
5
OP_T_THRES 是用于判断拷贝方式的阈值,通常是 8 字节或 16 字节,与架构相关。如果待拷贝的数据不小于 OP_T_THRES,则要经过更复杂的操作。op_t 表示单次操作指令加载和存储支持的最大类型,对应的长度 OPSIZ 用于内存对齐,通常为 8 字节。len -= (-dstp) % OPSIZ; 是针对目的地址的内存对齐计算。在 memcpy 函数中涉及到三个宏定义,依次拆解。
1.1 BYTE_COPY_FWD 与 BYTE_COPY_BWD
BYTE_COPY_FWD 是一个架构相关的宏定义,有几个不同架构下的实现,其中 generic 版本的代码如下,byte 的定义为 unsigned char。
1 |
从源码中可以发现,这是一个简单的以字节为单位,从源地址的起始地址开始,拷贝到目的地址开始的地址空间。另一个与之相似的宏为 BYTE_COPY_BWD,区别在于前者是 foreward 方向的拷贝,即拷贝的源地址和目的地址都是起始地址;而后者是 backward 的拷贝,源地址和目的地址指向的是一段地址空间末尾的地址。BYTE_COPY_BWD 的源码如下。
1 |
1.2 WORD_COPY_FWD
WORD_COPY_FWD 有数个架构相关的实现,通过内联汇编的方式优化。内联汇编的语法规则如下通过 asm 关键字启动内联汇编,后面接一行汇编指令,或一对大括号作用域下的汇编代码片段。 - “asm-qualifiers” 有三个选项,分别为: - volatile:关闭优化,取值自内存地址而非寄存器 - inline:内联限定符 - goto:此限定符将通知编译器 asm 中的语句可以跳转到 GotoLabels 中列出的某个标签 - “AssemblerTemplate”:由文本字符串构成,即具体的汇编指令代码 - “OutputOperands”:由 AssemblerTemplate 中的指令修改的 C 语言变量的逗号分隔列表,允许使用空列表 - “InputOperands” 是由 AssemblerTemplate 中的指令读取的以逗号分隔的 C 语言表达式列表,允许使用空列表 - “Clobbers”:由 AssemblerTemplate 更改的寄存器或其他值的逗号分隔列表,超出列为输出的值,允许使用空列表 - “GotoLabels”:当使用 asm goto 形式时,此部分包含 AssemblerTemplate 中的代码可能跳转到的所有 C 语言标签的列表 1
2
3
4
5
6
7
8
9
10
11
12asm [ asm-qualifiers ] (
AssemblerTemplate
: OutputOperands
[ : InputOperands
[ : Clobbers ] ])
asm asm-qualifiers (
AssemblerTemplate
:
: InputOperands
: Clobbers
: GotoLabels)
下面的代码段是 x86 上的 WORD_COPY_FWD 实现。dst_bp 和 src_bp 分别是目的地址和源地址,nbytes 是数据拷贝的字节数。nbytes_left 则表示剩余未拷贝的字节数,该变量将作用于宏外部的操作。
1 |
cld:复位方向标记位 DF=0,此时寄存器 ESI/EDI 递增,在后向拷贝WORD_COPY_BWD中,std指令设置方向标记位 DF=1,ESI/EDI 递减rep:当寄存器 ECX>0 时重复执行后面的指令movsl:该指令一次拷贝 4 个字节,当不足 4 字节时,nbytes_left不为 0,剩余的数据在宏外部以字节为单位拷贝=D:设置 EDI 目标索引寄存器为dst_bp=S:设置 ESI 源索引寄存器为src_bp=c:设置 ECX 计数器为__d0,对应到(nbytes)/4,即rep的重复次数memory:汇编代码对输入和输出操作数中列出的项以外的项执行内存读写
综上,首先设置 ESI 和 EDI 寄存器为 源地址和目的地址,并计算出拷贝次数,重复以 4 字节为单位执行拷贝操作,每轮结束后递增寄存器的值,并递减计数器。最后剩余数据不足 4 字节时,在宏外部以字节为单位执行拷贝。
1.3 PAGE_COPY_FWD_MAYBE
虚拟页拷贝,根据 PAGE_OFFSET 的定义,当源地址与目的地址在页上能够对齐时(即页内的偏移量相同),将使用三步操作进行拷贝。
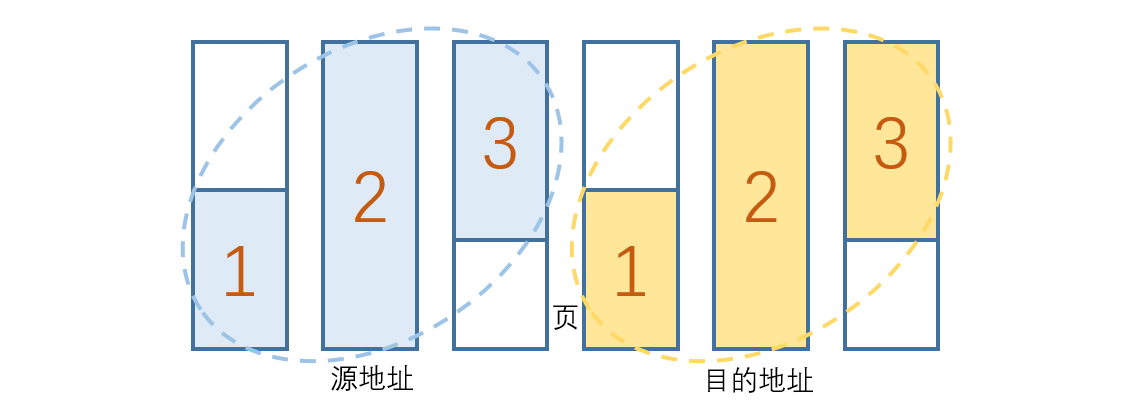
- 通过
WORD_COPY_FWD的方式以 4 字节为单位执行拷贝 - 完成页面 1 上的数据拷贝后,通过
PAGE_COPY_FWD的方式拷贝整个页面 - 剩余一个不完整的页通过
WORD_COPY_FWD的方式以 4 字节为单位执行拷贝 - 最后剩余不足 4 字节的数据按照字节为单位拷贝
1 |
PAGE_COPY_FWD 的源码如下,这里涉及的 __vm_copy 并不是 glibc 的函数,而是 mach kernel 中的原语。
1 |
1.4 memcpy 一图流总结
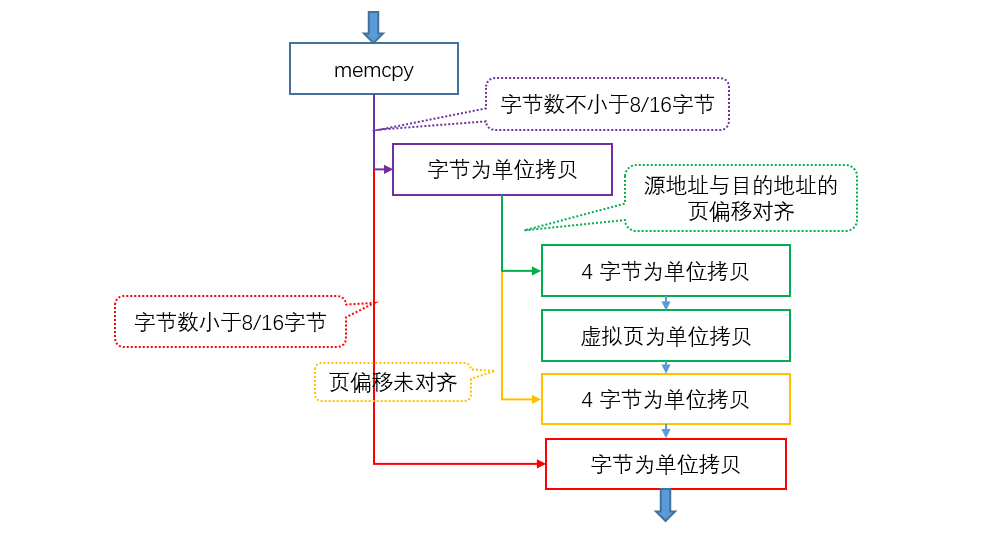
memcpy 函数存在安全问题,① 访问越界;② 内存重叠。内存重叠是指目的地址对应的内存空间与源地址的内存空间有重叠,这将导致拷贝结果出错。另外以上与架构相关的分析(例如 WORD_COPY 以 4 字节为单位的拷贝)都是基于 x86 的,在其他平台上可能有不同的取值。
2. memmove
源地址空间与目的地址空间的分布存在四种可能性,如下图所示。①②两种情况不存在重叠问题,对于第③种源地址空间在目的地址空间之后,memcpy 执行完后,会导致源地址空间的数据被覆盖;对于第④中情况,memcpy 在拷贝一开始,就将源地址空间尾部重叠部分的数据覆盖,这将使源地址与目的地址指向的数据都出错。

memmove 可以部分地解决 memcpy 中存在的内存重叠问题(只针对目的地址空间而言),如果严格要求内存拷贝,而不是内存区域数据的转移,则需要人为地保证源地址与目的地址的空间不重叠。memmove 函数的定义为: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36rettype inhibit_loop_to_libcall
MEMMOVE (a1const void *dest, a2const void *src, size_t len)
{
unsigned long int dstp = (long int) dest;
unsigned long int srcp = (long int) src;
if (dstp - srcp >= len)
{
dest = memcpy (dest, src, len);
if (len >= OP_T_THRES)
{
len -= (-dstp) % OPSIZ;
BYTE_COPY_FWD (dstp, srcp, (-dstp) % OPSIZ);
PAGE_COPY_FWD_MAYBE (dstp, srcp, len, len);
WORD_COPY_FWD (dstp, srcp, len, len);
}
BYTE_COPY_FWD (dstp, srcp, len);
}
else
{
srcp += len;
dstp += len;
if (len >= OP_T_THRES)
{
len -= dstp % OPSIZ;
BYTE_COPY_BWD (dstp, srcp, dstp % OPSIZ);
WORD_COPY_BWD (dstp, srcp, len, len);
}
BYTE_COPY_BWD (dstp, srcp, len);
}
RETURN (dest);
}
memmove 根据源地址与目的地址两种类型的空间关系,采取不同的拷贝方式,以保证数据的安全。源码中通过无符号数 dstp - srcp >= len 的判断,实现了区间的划分: - ① 目的地址在源地址左侧,或目的地址在源地址右侧但没有与源地址空间发生重叠 - ② 目的地址在源地址的右侧,且两者之差小于源地址的空间偏移量,这种情况下目的地址空间左侧重叠了源地址空间的右侧
对于第一种情况,memmove 采取 memcpy 的前向拷贝方式进行拷贝;对于第二种情况,采取从后向前的拷贝,但是与 memcpy 略微不同的处理方式在于:后向拷贝没有涉及虚拟页表方式的拷贝,从而避免覆盖的风险。
3. mempcpy
memcpy 和 memmove 在执行完成后,都会返回目的地址空间的起始地址,然而在某些情况下,我们希望执行完拷贝操作之后,返回的指针指向拷贝结束位置向后的一个地址,以便于在接下来从结束位置再继续向后写数据,这时就会用到 mempcpy,其定义为: 1
可以看到该函数仍然是通过 memcpy 来执行拷贝的,仅仅只是在返回的目的地址基础上简单地加上了拷贝内容的长度。
4. memccpy
memccpy 将不超过 n 个字节的源地址空间数据拷贝到目的地址空间,遇到字节 c 时停止。返回目的地址空间中字节 c 对应地址的后一个地址,如果未找到字节 c,则返回 NULL。源码定义如下: 1
2
3
4
5
6
7
8
9
10void *memccpy (void *dest, const void *src, int c, size_t n)
{
void *p = memchr (src, c, n);
if (p != NULL)
return __mempcpy (dest, src, p - src + 1);
memcpy (dest, src, n);
return NULL;
}
该函数非常好理解,首先在 n 长度的源地址空间中查找字节 c,memchr 返回查找到的 c 的地址。 - 如果 c 找到,则从源地址开始,通过 mempcpy 一直拷贝到字节 c,并返回字节 c 后面的一个地址 - 如果 c 未找到,则通过 memcpy 完成全部拷贝,并返回 NULL
5. strcpy
字符串拷贝要通过两个步骤实现:① 计算字符串长度;② 通过 memcpy 执行拷贝。源码如下: 1
2
3
4char *STRCPY (char *dest, const char *src)
{
return memcpy (dest, src, strlen (src) + 1);
}strlen 返回的长度不包括字符串末尾的 '\0',所以调用 memcpy 时拷贝的长度需要 +1。
6. stpcpy
拷贝过程与 strcpy 相似,不同点在于 stpcpy 执行完字符串拷贝后,返回的地址指向字符串末尾的 '\0'。
1 | char *STPCPY (char *dest, const char *src) |
7. strncpy
如果我们在执行拷贝时,不知道源字符串有多大,而目的地址空间长度有限,为了防止越界,必须要设置最大拷贝长度,stpncpy 可以很好的完成这一任务。
1 | char *STRNCPY (char *s1, const char *s2, size_t n) |
- 函数
strnlen与strlen稍许不同,它的返回值是字符串 s 的实际长度与 n 的最小值 - 第二步,只要源字符串的长度小于 n,就首先将目的地址空间剩余的部分填充为
'\0' - 最后执行拷贝,返回目的地址空间的首地址
8. stpncpy
与 strncpy 类似,stpncpy 执行不超过 n 的拷贝后,如果字符串在目的地址空间中未越界,则返回字符串末尾 '\0' 之后的一个地址;如果越界,则返回目的地址空间最末尾的地址。
1 | char *STPNCPY (char *dest, const char *src, size_t n) |
(完)